 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould LLMs, $\textit{like}$, Generate How Users Talk? Building Dialect-Accurate Dialog[ue]s Beyond the American Default with MDial
Jan 30, 2026More than 80% of the 1.6 billion English speakers do not use Standard American English (SAE) and experience higher failure rates and stereotyped responses when interacting with LLMs as a result. Yet multi-dialectal performance remains underexplored. We introduce $\textbf{MDial}$, the first large-scale framework for generating multi-dialectal conversational data encompassing the three pillars of written dialect -- lexical (vocabulary), orthographic (spelling), and morphosyntactic (grammar) features -- for nine English dialects. Partnering with native linguists, we design an annotated and scalable rule-based LLM transformation to ensure precision. Our approach challenges the assumption that models should mirror users' morphosyntactic features, showing that up to 90% of the grammatical features of a dialect should not be reproduced by models. Independent evaluations confirm data quality, with annotators preferring MDial outputs over prior methods in 98% of pairwise comparisons for dialect naturalness. Using this pipeline, we construct the dialect-parallel $\textbf{MDialBench}$mark with 50k+ dialogs, resulting in 97k+ QA pairs, and evaluate 17 LLMs on dialect identification and response generation tasks. Even frontier models achieve under 70% accuracy, fail to reach 50% for Canadian English, and systematically misclassify non-SAE dialects as American or British. As dialect identification underpins natural language understanding, these errors risk cascading failures into downstream tasks.
PolyLingua: Margin-based Inter-class Transformer for Robust Cross-domain Language Detection
Dec 10, 2025Language identification is a crucial first step in multilingual systems such as chatbots and virtual assistants, enabling linguistically and culturally accurate user experiences. Errors at this stage can cascade into downstream failures, setting a high bar for accuracy. Yet, existing language identification tools struggle with key cases -- such as music requests where the song title and user language differ. Open-source tools like LangDetect, FastText are fast but less accurate, while large language models, though effective, are often too costly for low-latency or low-resource settings. We introduce PolyLingua, a lightweight Transformer-based model for in-domain language detection and fine-grained language classification. It employs a two-level contrastive learning framework combining instance-level separation and class-level alignment with adaptive margins, yielding compact and well-separated embeddings even for closely related languages. Evaluated on two challenging datasets -- Amazon Massive (multilingual digital assistant utterances) and a Song dataset (music requests with frequent code-switching) -- PolyLingua achieves 99.25% F1 and 98.15% F1, respectively, surpassing Sonnet 3.5 while using 10x fewer parameters, making it ideal for compute- and latency-constrained environments.
Efficiently predicting high resolution mass spectra with graph neural networks
Jan 26, 2023



Identifying a small molecule from its mass spectrum is the primary open problem in computational metabolomics. This is typically cast as information retrieval: an unknown spectrum is matched against spectra predicted computationally from a large database of chemical structures. However, current approaches to spectrum prediction model the output space in ways that force a tradeoff between capturing high resolution mass information and tractable learning. We resolve this tradeoff by casting spectrum prediction as a mapping from an input molecular graph to a probability distribution over molecular formulas. We discover that a large corpus of mass spectra can be closely approximated using a fixed vocabulary constituting only 2% of all observed formulas. This enables efficient spectrum prediction using an architecture similar to graph classification - GrAFF-MS - achieving significantly lower prediction error and orders-of-magnitude faster runtime than state-of-the-art methods.
Multi-scale Sinusoidal Embeddings Enable Learning on High Resolution Mass Spectrometry Data
Jul 06, 2022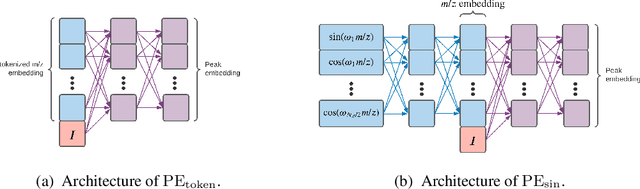
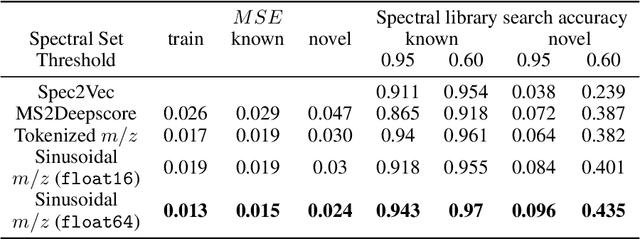
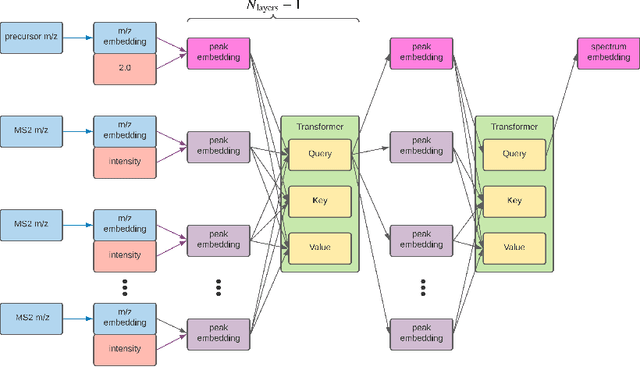
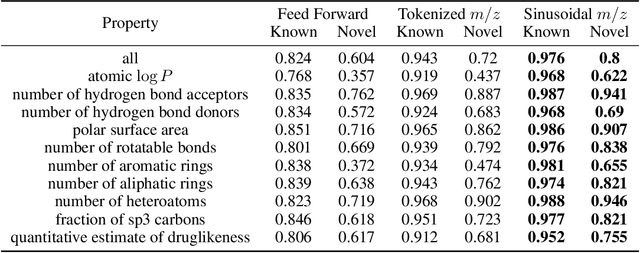
Small molecules in biological samples are studied to provide information about disease states, environmental toxins, natural product drug discovery, and many other applications. The primary window into the composition of small molecule mixtures is tandem mass spectrometry (MS2), which produces data that are of high sensitivity and part per million resolution. We adopt multi-scale sinusoidal embeddings of the mass data in MS2 designed to meet the challenge of learning from the full resolution of MS2 data. Using these embeddings, we provide a new state of the art model for spectral library search, the standard task for initial evaluation of MS2 data. We also introduce a new task, chemical property prediction from MS2 data, that has natural applications in high-throughput MS2 experiments and show that an average $R^2$ of 80\% for novel compounds can be achieved across 10 chemical properties prioritized by medicinal chemists. We use dimensionality reduction techniques and experiments with different floating point resolutions to show the essential role multi-scale sinusoidal embeddings play in learning from MS2 data.
Hidden Biases in Unreliable News Detection Datasets
Apr 20, 2021
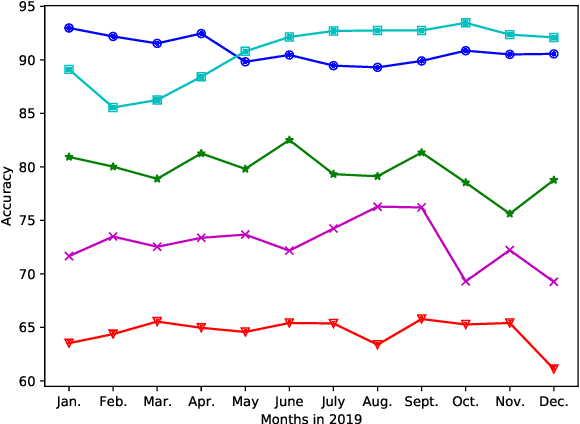


Automatic unreliable news detection is a research problem with great potential impact. Recently, several papers have shown promising results on large-scale news datasets with models that only use the article itself without resorting to any fact-checking mechanism or retrieving any supporting evidence. In this work, we take a closer look at these datasets. While they all provide valuable resources for future research, we observe a number of problems that may lead to results that do not generalize in more realistic settings. Specifically, we show that selection bias during data collection leads to undesired artifacts in the datasets. In addition, while most systems train and predict at the level of individual articles, overlapping article sources in the training and evaluation data can provide a strong confounding factor that models can exploit. In the presence of this confounding factor, the models can achieve good performance by directly memorizing the site-label mapping instead of modeling the real task of unreliable news detection. We observed a significant drop (>10%) in accuracy for all models tested in a clean split with no train/test source overlap. Using the observations and experimental results, we provide practical suggestions on how to create more reliable datasets for the unreliable news detection task. We suggest future dataset creation include a simple model as a difficulty/bias probe and future model development use a clean non-overlapping site and date split.